难怪 Skill 不好用?来看看 Google 总结的 5 种
- 来源:
- 浮云设计
- 时间:
- 2026-04-12 02:09:54
- 阅读:
- 224
当一个 Agent 真正开始“干活”时,你就会发现,决定它靠不靠谱的,往往是你给它的 Skill。
很多开发者一提到 SKILL.md,第一反应往往是格式、目录结构、YAML 语法,或者是 assets 和 references 文件夹。
但说实话,这些外在形式已经没那么重要了。
真正拉开差距的,是 Skill 的内部逻辑设计。
Google 在观察了大量生态内的实践后,将常见的设计思路归纳为 5 种 Skill 设计模式。
今天,我们就来拆解这 5 种模式的运转逻辑。
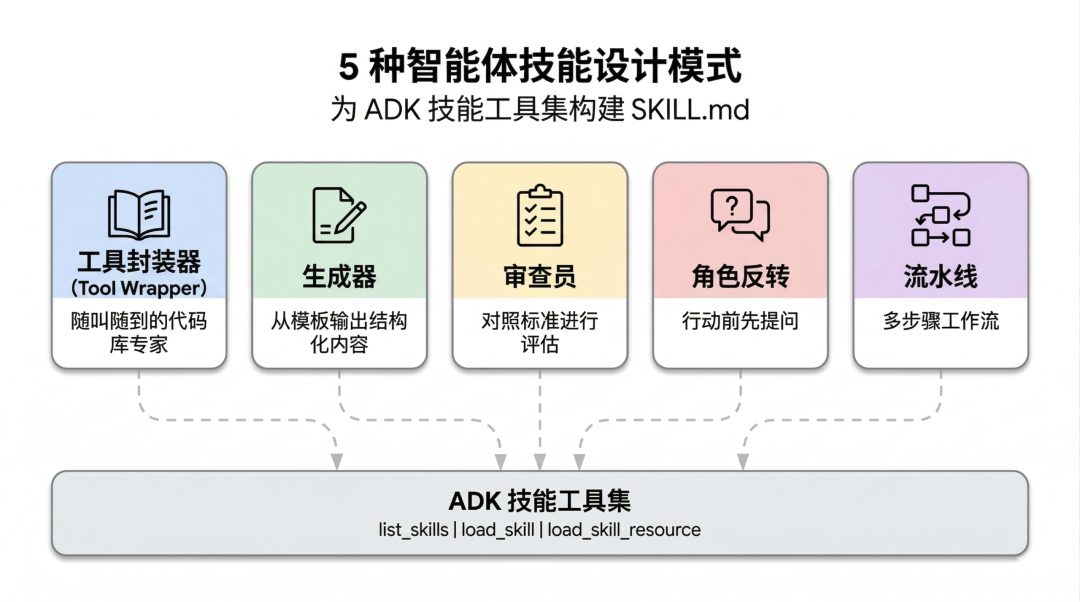
模式一:工具封装器 (Tool Wrapper) ,随叫随到的外挂专家
“工具封装器”能让你的 Agent 在需要时,立即获得某个特定库的上下文信息,做到“随叫随到”。
简单说就是,把某个特定领域的知识,做成一个“按需加载”的技能包。
与其把繁琐的规则全部死死地写进系统提示词里,白白浪费大模型的上下文空间,不如将它们打包成一项专属的 Skill。
这是实现起来最简单的一种模式。
你只需要在 SKILL.md 里设定一个“触发词”。一旦用户的提示词命中了特定关键词,Agent 就会动态从 references/目录中加载相关文档,并将其作为绝对准则来执行。
通过这套机制,你可以轻松地将团队内部的代码规范,或是某个框架的最佳实践,无缝接入到开发者的日常工作流中。
Agent 只有在真正需要时,才会召唤这位“外挂专家”。
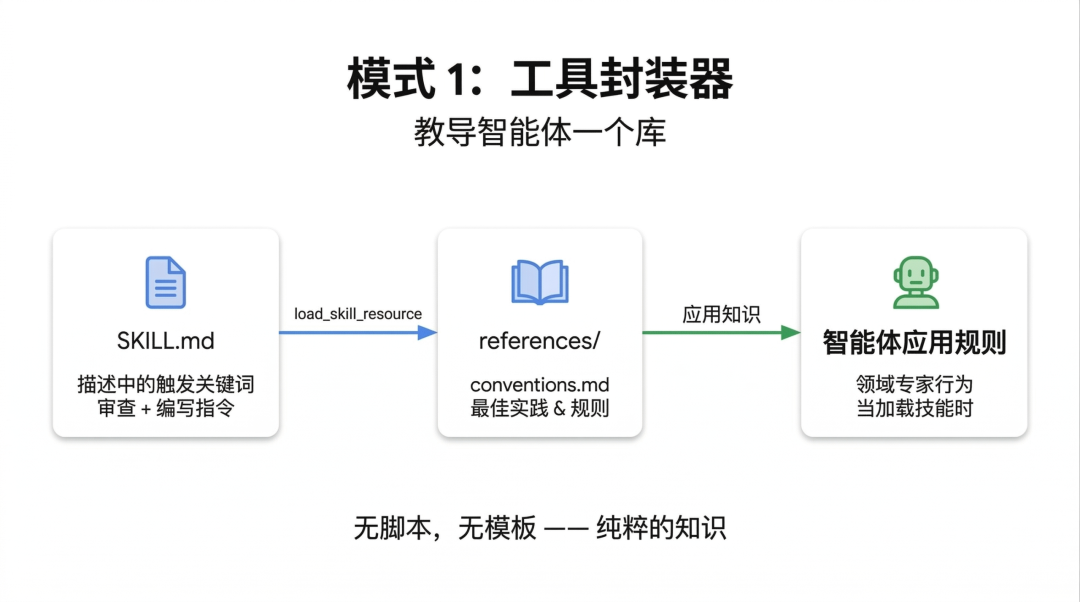
模式二:生成器 (Generator),专治各种“排版不服”
如果说“工具封装器”(Tool Wrapper)的作用,是把知识准确“装”进 Agent 里。
那么“生成器”这个模式的核心理念是给 AI 发一张“填空题试卷”,确保输出的高度一致性。
你有没有发现,哪怕是让 AI 写同一份报告,它也可能今天给你列个表格,明天给你整三个大段落。对于需要标准化输出的场景来说,这种不确定性简直是灾难。
生成器模式是怎么解决的?它把生成过程变成了标准化流水线来解决了这个问题。
它巧妙地利用了两个维度的信息:
一是“输出模板”,告诉 AI 最终的框架长什么样,保存在 assets/ 目录;
二是“样式指南”,告诉 AI 该用什么语气和格式,保存在references/ 目录。
在这个模式下,Skill 就像一位尽职的“项目经理”,发现信息缺失就会停下来主动找用户要,拿到所有信息后再老老实实按模板填空。
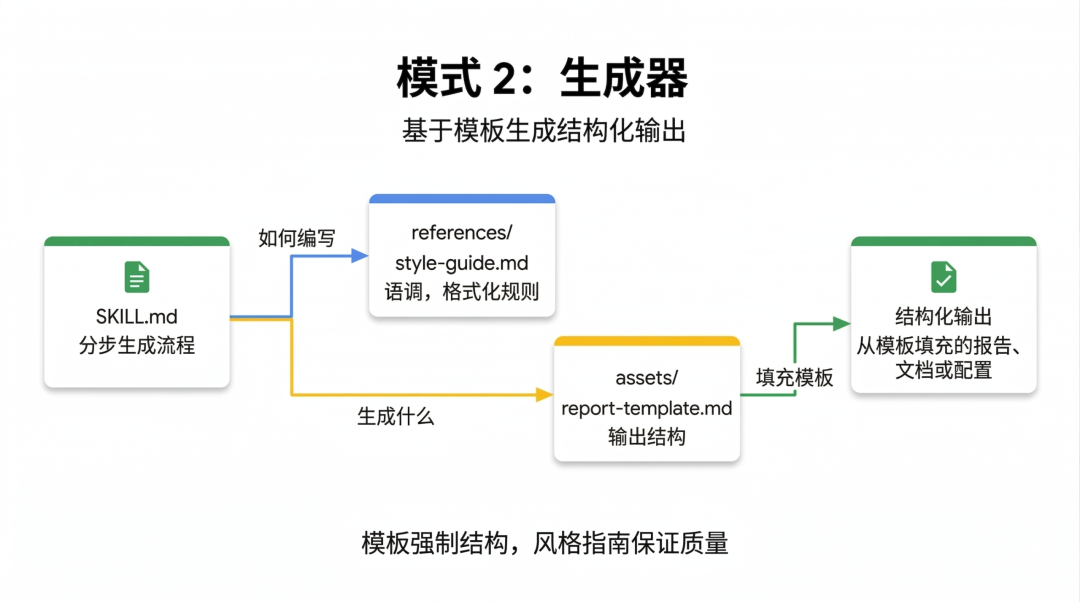
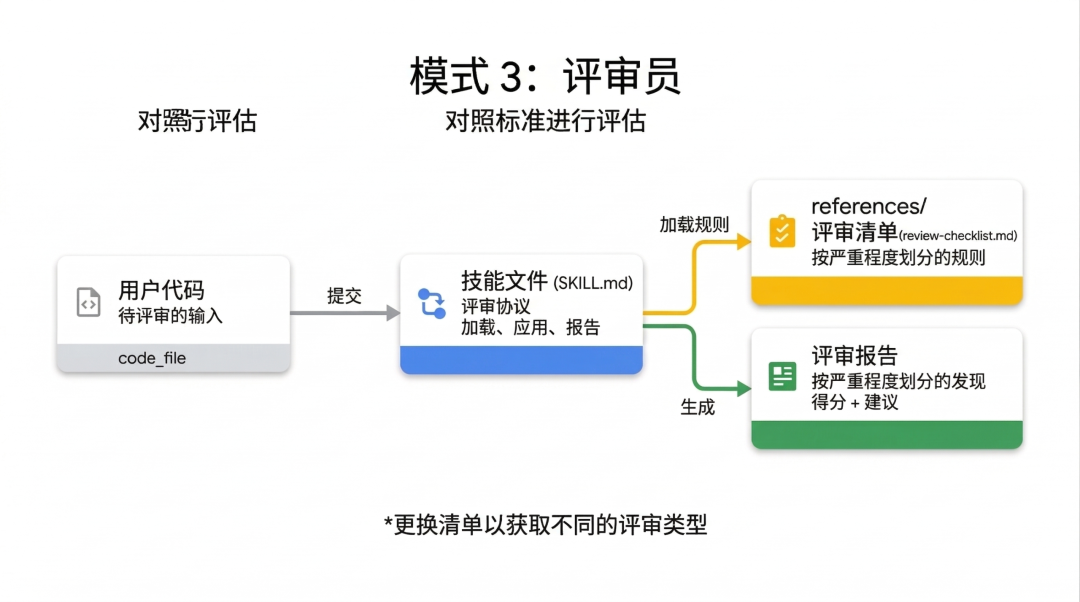
模式三:审查员 (Reviewer),铁面无私的质检员
“审查员”模式的核心理念,把两件事清楚地拆开了,“检查什么”和“怎么检查”。
如果你把所有的代码审查规则全写死在核心逻辑里,那它就只能干这一件事。
但“审查员”模式的精髓在于:Skill 只负责当“判官”执行检查,而具体的“条文”则从外部动态加载。
你可以把模块化的评分标准存放在独立的 references/review-checklist.md 文档中。
这种设计最妙的地方在于极高的灵活性:SKILL.md 里的基础设施完全不用改,只需替换检查清单。
今天给它塞一份 Python 代码规范,它就是代码审查专家;明天换成安全检查清单,它瞬间摇身一变,成了顶级的安全审计员。
模式四:角色反转 (Inversion),谋定而后动的老司机
AI 天生就喜欢揣测,并且总是迫不及待地想要立刻生成内容。
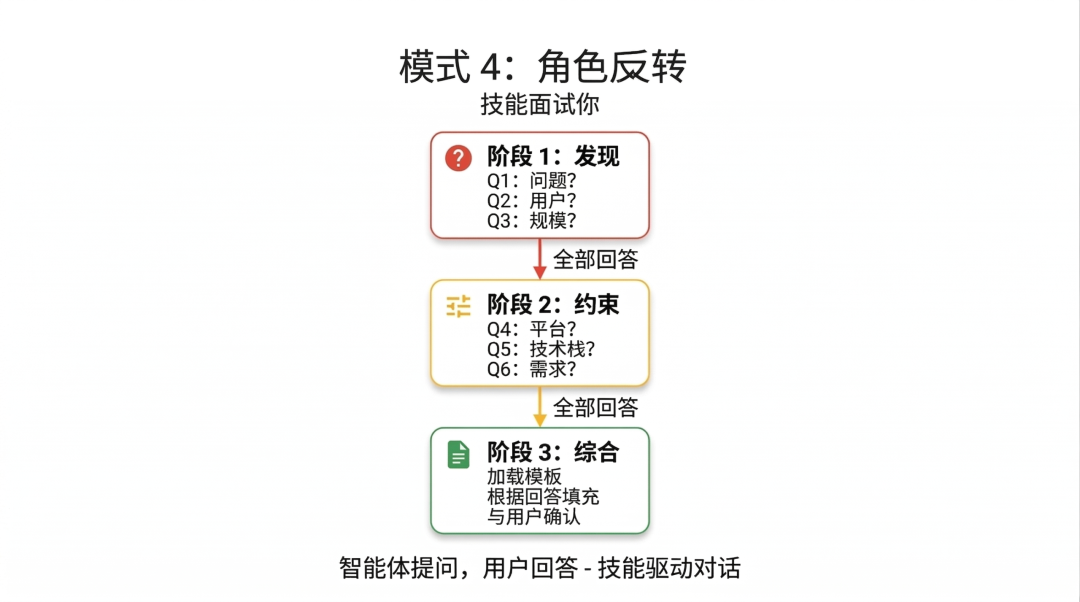
“角色反转”模式就是为了改变这种单向的驱动关系。它让 AI 变成记者,主动来采访你。
在这个模式下,不再是用户绞尽脑汁地写长篇提示词,而是让智能体“反客为主”变成采访者。
你必须给 AI 下达死命令:在没有问清所有背景之前,一行代码都不准写!
它会像个成熟的咨询顾问一样,按阶段向你发问:
“你想解决什么问题?”“技术栈有偏好吗?”“预算是多少?”
这能强制 Agent 老老实实地收集上下文背景信息,而不是急着动手。在彻底明白你的需求之前,Agent 绝不会输出最终方案。
这才是真正懂行的数字员工。
模式五:流水线 (Pipeline),一步一个脚印的车间主任
面对复杂的任务,最怕的不是不会做,而是中途漏步骤、跳步骤,或者把关键要求直接忽略掉。
比如让它生成文档,它可能连代码里的变量还没认全,就直接开始瞎编使用说明了。
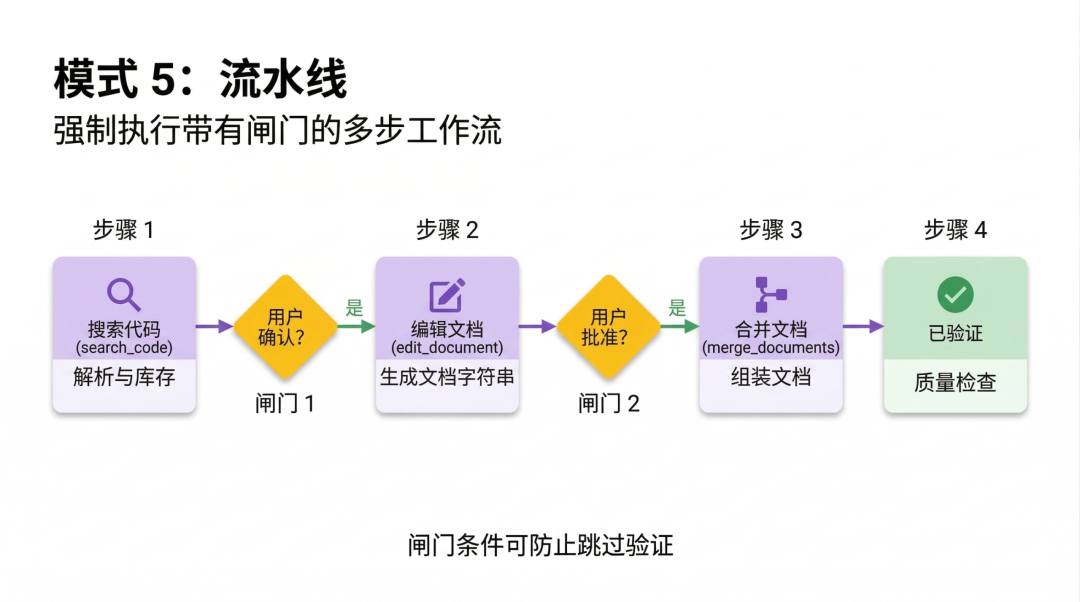
“流水线”模式就是为了解决这个问题而生的,通过设置强制性的“打卡点”,逼着 AI 必须按顺序完成多步骤任务,中间不许偷懒。
比如第一步盘点 API 接口,第二步写注释,并且必须向用户确认无误后,才能进入第三步生成最终文档。
它如果想跳到第三步?门都没有!必须先把你叫过来:“这几个注释您看写得对吗?”你点头了,它才能继续往下走。
这样做最大的好处是,充分利用了所有的可选目录。在不同步骤中,只加载当前步骤真正需要的参考文件和模板。
这样既能保证流程严谨,也能极大地保持了上下文窗口 (context window) 的干净整洁。
总结:小孩子才做选择,成熟的开发者全都要!
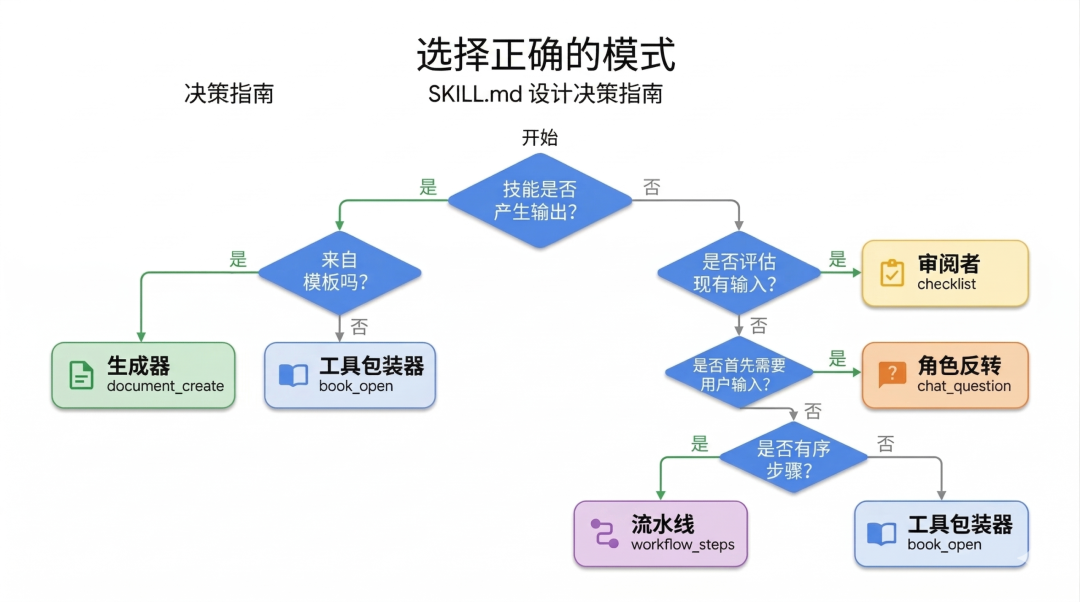
这五种模式绝对不是孤立的。最厉害的开发者,往往是把它们像乐高积木一样拼起来用。
试想一下这样一个工作流:
你的 AI 先用 角色反转(Inversion)问清楚你想干嘛;接着用 生成器(Generator) 调出模板开始填空;生成完之后,通过 流水线(Pipeline) 进入下一步;最后请出 审查员(Reviewer) 用外部安全标准给自己写的代码做个交叉验证。
一套顺滑、强大、绝不翻车的 AI 智能体工作流,就这么诞生了!
最近文章列表:
[1] 智能体 Skill 入门教程(附下载地址)
[2] 两年踩坑,换来这条 AI 学习路径
[3] Skill 到底是什么?跟 MCP 有什么区别?
[4] AI 是怎么学会唠嗑的?系统提示词又是什么?
[5] Claude 控诉中国 AI 组团“偷家”?到底什么是“大模型蒸馏”?
[6] 价值 3000 元的 AI 内部培训课,今天我把它“开源”了
[7] 拆解 AI 的大脑,看懂谷歌“弱智”提示词
[8] 日均30万亿!拆解 AI 时代的“计量单位” Token
[9] 2 分钟讲透:为什么 AI 会胡说八道?(附避坑指南)
[10] AI 的回复怎么完美转 Word?只要看懂这个格式 Markdown,效率翻倍
[11] 学习 AI 的最大障碍,不懂大模型背后的灵魂
[12] Vibe Coding 提示词指南(内附编程提示词速查表)
[13] 为什么你的 AI 用得没别人好?AI 真正的核心不是提示词,而是逆向工程
预览时标签不可点