GitHub 狂揽 6.2 万 Star,Hermes Agent
- 来源:
- 创意工坊
- 时间:
- 2026-04-14 01:43:59
- 阅读:
- 210
最近几周,全球 AI 开发者的 X 和 GitHub,几乎都绕不开一个名字:Hermes Agent。
从 2 月底开源首月破 2.2 万星,到 v0.8.0 发布后单日新增 6400+ 星,Hermes Agent 在不到两个月的时间里,总 Star 数已飙升至 6.2 万,几乎是“住在”了 GitHub 全球趋势榜第一。
图片来源:Github
有人说它是 OpenClaw 的最强平替,有人说它开启了“自进化 Agent”的元年。
01|为什么 Hermes Agent 会让这么多人上头?
Hermes Agent 真正吸引人的地方,不只是“又来了一个新的 Agent”。
它更像是在回答一个很多开发者都在关心的问题:
如果 Agent 不只是完成一次任务,而是能从任务中沉淀技能、保留记忆、逐步形成更稳定的做事方式,它会不会更接近大家真正想要的个人 AI 系统?
这也是 Hermes Agent 最打动人的地方。
按照官方仓库的描述,它强调的是一套“越用越会”的机制:
它会从经验中生成技能、在使用中不断改进、搜索过去的对话,并在跨会话中逐渐形成对用户更深的理解。v0.8.0 版本又进一步加入了后台任务自动通知、跨平台实时切换模型等能力,让这套系统感更强了。
说白一点,Hermes Agent 让很多人第一次更具体地感受到:
Agent 的上限,也许不只取决于“这一次会不会做”,
还取决于“下一次会不会因为过去做过而做得更好”。
这件事,确实很容易让人上头。
02|但比“火”更现实的问题,是怎么把它真正跑起来
热度归热度,落地是另一回事。
Hermes Agent 火了之后,很多人的第一反应是想试。
但真正劝退人的,往往不是它的概念,而是它背后的那条运行链路。
你会很快遇到这些问题:
模型怎么接?
环境怎么配?
本地怎么跑?
速度能不能接受?
如果不想长期烧 API,能不能直接用本地模型把它跑顺?
官方仓库当然已经给了很多部署方式。Hermes Agent 支持运行在低成本 VPS、GPU 集群,也支持空闲时几乎不花钱的 serverless 基础设施。问题在于,“能部署” 和 “真好用” 之间,往往还隔着很长一段距离。
很多项目都是这样:看起来很强,演示也很惊艳,
但一到真正自己动手,就开始被环境、依赖、推理速度和本地部署链路劝退。
所以,Hermes Agent 这波热度背后,真正值得解决的问题其实非常明确:
怎么把一个很强的 Agent,变成一个真正能在本地稳定用起来的 Agent。
03|破局:OmniInfer 接入,这次是真的“真能用”
社区里到处在讨论怎么接各种模型。不过你会发现,大部分教程聊的都是接云端 API —— OpenRouter、DeepSeek、Kimi 之类的。
那一个很自然的问题就来了:能不能完全不依赖云端,模型跑在自己的设备上,然后让 Hermes Agent 来调?
答案是:能。而且比你想的简单得多。
关键角色是 OmniInfer。它是一个跨平台的端侧推理引擎,装完之后跑一个 `./omniinfer serve`,你的设备就变成了一个本地版 OpenAI API 服务,暴露标准的 `/v1/chat/completions` 接口。Hermes Agent 那边只需要填一个地址就能对接上。
本文就是一步一步把这条链路跑通的完整教程。每条命令都实际执行过,终端输出都是真的。你跟着复制粘贴就能跑通。
04|手把手教你:5 分钟把 Hermes Agent 跑在本地
说了这么多,接下来不谈概念,直接上手。
如果你前面已经被 Hermes Agent 种草,但又担心环境太复杂、链路太长、自己一上来就踩坑,那这一部分就是给你准备的。
这次我们不讲玄学,不绕弯子,
就做一件事:
把 Hermes Agent 真正跑起来。
而且不是停留在“理论上可以”,
而是尽量用一条更直接、更省事的路径,把它接进 OmniInfer,让它真正进入可用状态。
整个流程并不复杂,核心就分三步:
第一步:安装 OmniInfer
1.1 运行安装脚本打开终端,Mac和Linux用户复制这一行:curl -fsSL https://raw.githubusercontent.com/omnimind-ai/OmniInfer/main/scripts/install.sh | bash
Windows 用户用 PowerShell:irm https://raw.githubusercontent.com/omnimind-ai/OmniInfer/main/scripts/install.ps1 | iex
回车之后你会看到安装的欢迎横幅:

1.2 脚本第 3 步:选择推理后端(重要!需要你选)
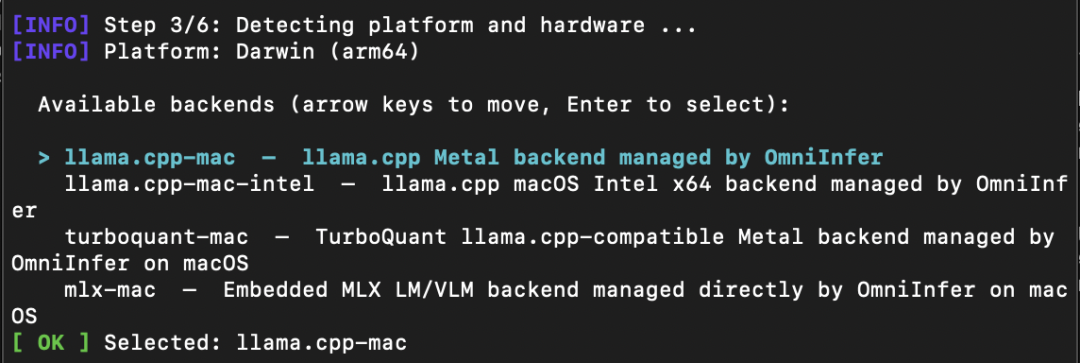
这里需要你选一个推理后端。 脚本会根据你的操作系统和硬件,列出所有可用的后端。用上下方向键移动光标,回车键确认选择。
建议:直接选第一个(默认高亮的那个)就行。 脚本默认推荐的通常就是你设备上最合适的后端。
1.3 配置本地模型可以直接回车,推荐模型为Qwen2.5系列(也可以自己下载Gemma 4等放在本地模型库),选好模型后,脚本自动下载到 OmniInfer/models/ 目录下: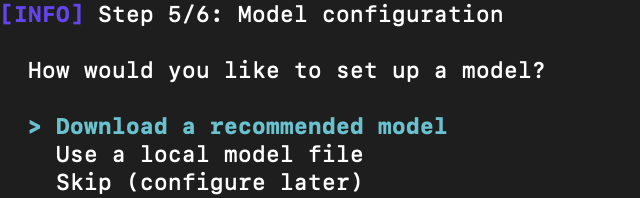
如果你已经有模型文件了(比如之前从 HuggingFace 下载的 GGUF 文件),选这个,然后输入模型的完整路径:
Enter model path: /Users/用户名/OmniInfer/models/qwen2.5-7b-instruct-q4_k_m.gguf[ OK ] Model: /Users/用户名/OmniInfer/models/qwen2.5-7b-instruct-q4_k_m.gguf
1.4 模型运行
如果你在第 5 步选了模型(下载或本地),脚本会自动加载模型并进入一个简单的对话界面,让你当场试试效果。输入 exit 退出。

1.5 启动 API 服务
安装脚本跑完后会自动退出服务。我们需要手动启动 API 服务 —— 这是让 Hermes Agent 能调用本地模型的关键:
cd /你的路径/OmniInfer./omniinfer serve
启动成功后你会看到这样的日志输出:
2026-04-12 18:02:23.617 INFO [runtime] RuntimeManager initialized: platform=mac2026-04-12 18:02:23.617 INFO [runtime] Backends discovered: llama.cpp-mac, mlx-mac, ...2026-04-12 18:02:23.618 INFO [startup] ============================================================2026-04-12 18:02:23.618 INFO [startup] OmniInfer 0.2 starting2026-04-12 18:02:23.618 INFO [startup] Python 3.9.62026-04-12 18:02:23.618 INFO [startup] OS: Darwin 24.6.0 arm642026-04-12 18:02:23.621 INFO [startup] RAM available: 9.91 GiB2026-04-12 18:02:23.624 INFO [startup] GPU: Apple Metal (unified memory)2026-04-12 18:02:23.624 INFO [startup] Config: host=127.0.0.1 port=90002026-04-12 18:02:23.624 INFO [startup] Available backends: llama.cpp-mac, mlx-mac, ...2026-04-12 18:02:23.627 INFO [gateway] OmniInfer listening on http://127.0.0.1:9000
重点看最后一行:OmniInfer listening on http://127.0.0.1:9000 —— 这表示 API 服务已经在 9000 端口监听了。
1.6 加载模型到 API 服务
./omniinfer serve 启动的是一个空服务(没有模型),我们需要告诉它加载哪个模型。另开一个终端窗口,执行:
curl -X POST http://127.0.0.1:9000/omni/model/select \ -H "Content-Type: application/json" \ -d '{"model": "/你的路径/OmniInfer/models/Qwen3.5-0.8B-Q4_K_M.gguf"}'
把路径换成你实际的模型文件路径! 如果你用安装脚本下载的模型,默认在 OmniInfer/models/ 目录下。
实际返回:
{ "ok": true, "selected_backend": "llama.cpp-mac", "selected_model": "/Users/.../models/Qwen3.5-0.8B-Q4_K_M.gguf", "selected_mmproj": null, "selected_ctx_size": null}
"ok": true 就表示模型加载成功了。也可以用 CLI 方式:./omniinfer model load -m /路径/模型.gguf,效果一样。
1.7 验证 API 是否正常工作
先查模型列表:
curl http://127.0.0.1:9000/v1/models
返回:
{ "object": "list", "data": [ { "id": "Qwen3.5-0.8B-Q4_K_M.gguf", "object": "model", "owned_by": "omniinfer" } ]}
再发一条对话测试:
curl http://127.0.0.1:9000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "messages": [{"role": "user", "content": "你好,用一句话介绍你自己"}], "max_tokens": 100 }'
实际返回:
{ "choices": [ { "message": { "role": "assistant", "content": "你好!我是 Qwen3.5,阿里巴巴集团最新推出的超大规模语言模型..." } } ], "model": "Qwen3.5-0.8B-Q4_K_M.gguf", "usage": { "prompt_tokens": 18, "completion_tokens": 44, "total_tokens": 62 }, "timings": { "prompt_per_second": 436.01, "predicted_per_second": 167.20 }}
模型正常回复了。注意看 timings 里的速度 —— prompt 处理 436 tokens/s,生成 167 tokens/s,这是 0.8B 小模型在 Apple Silicon 上的表现,基本感觉不到延迟。更大的模型速度会慢一些,但 7B Q4 在 16GB Mac 上也能达到 30~50 tokens/s,日常使用完全够了。
到这里,OmniInfer 这边就全部搞定了。 记住这个地址:http://127.0.0.1:9000,后面配 Hermes Agent 要用。
第二步:安装 Hermes Agent 并接入 OmniInfer
2.1 一行命令安装Hermes Agent:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
脚本会自动帮你装好 Python 3.11、Node.js v22、ripgrep 等一整套依赖,以及 Hermes Agent 本体和全局 hermes 命令。全程自动,不需要你操心。
安装过程中脚本会弹出交互式向导,问你选哪个模型提供商。如果此时 OmniInfer 的 ./omniinfer serve 已经在运行了,可以直接在这一步就配好 —— 往后面看 2.2 节的操作就行,流程完全一样。如果安装时先跳过了也没关系,装完随时用 hermes model 重新配。
装完后重新加载 shell:
source ~/.bashrc # bash 用户source ~/.zshrc # zsh 用户(macOS 默认是 zsh)
验证一下:
hermes --version
输出如下信息则表明安装成功:
Hermes Agent v0.8.0 (2026.4.8)Project: /Users/wangtuowei/.hermes/hermes-agentPython: 3.11.13OpenAI SDK: 2.31.0Up to date
2.2 运行 hermes model 选择 API
现在来告诉 Hermes 用我们本地的 OmniInfer。确保 OmniInfer 的 ./omniinfer serve 还在运行,然后执行:
hermes model
弹出提供商选择菜单。Hermes 支持的提供商非常多,菜单第一页是这些:
? Select a provider: Nous Portal (subscription, zero-config) OpenAI Codex (ChatGPT OAuth) Anthropic (Claude) OpenRouter (200+ models) Qwen OAuth GitHub Copilot Hugging Face More providers... Cancel
如果你之前已经配过一次 OmniInfer 的自定义端点,它会被自动保存,并且直接出现在这个菜单的第一页,类似这样:
? Select a provider: Nous Portal (subscription, zero-config) OpenAI Codex (ChatGPT OAuth) ...❯ Local (127.0.0.1:9000) — Qwen3.5-0.8B-Q4_K_M.gguf More providers... Cancel
如果是第一次配,需要往下翻,选 "More providers...",在第二页找到:
... Alibaba Cloud / DashScope❯ Custom endpoint (enter URL manually) Cancel
选 "Custom endpoint (enter URL manually)",回车。
2.3 填写连接信息
选完 Custom endpoint 后,Hermes 会依次问你 3 个信息:
第一、API 地址:
? Base URL: http://127.0.0.1:9000/v1
输入 http://127.0.0.1:9000/v1,回车。
第二、API Key:
? API Key (leave empty for local):
直接回车跳过,本地服务不需要认证。
第三、模型名称:
这一步很可能不用你手动填 —— Hermes 输入完地址后会自动探测 OmniInfer 的 /v1/models 接口。如果 OmniInfer 里只加载了一个模型,Hermes 会直接自动识别:
✓ Auto-detected model: Qwen3.5-0.8B-Q4_K_M.gguf
如果加载了多个模型,Hermes 会列出来让你选。
配置完成后确认:
✓ Model configured: Qwen3.5-0.8B-Q4_K_M.gguf via custom endpoint
同时这个端点会被自动保存到 ~/.hermes/config.yaml 的 custom_providers 里。下次跑 hermes model 时就直接出现在第一页了,不需要再从头填。
第三步:启动 Hermes,开始真正使用
确保 OmniInfer 还在运行(第一步启动的 ./omniinfer serve),然后运行:
hermes
进入 Hermes 的交互式对话界面。随便问一句:
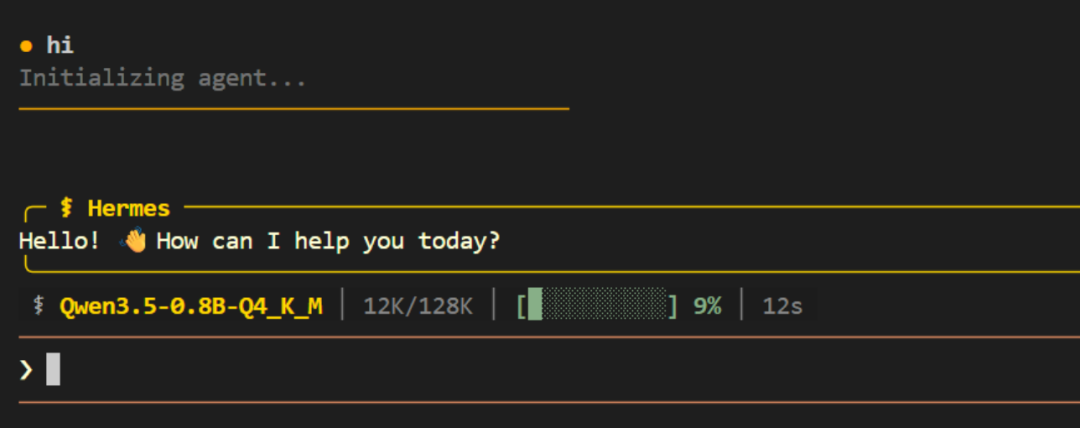
如果模型正常回复了,整条链路跑通了。
试试 Agent 的真正能力 —— 它不只是聊天,它能主动调工具:
> 帮我看看当前目录有哪些文件> 写个 Python 脚本计算斐波那契数列前 20 项
Hermes 会自动调终端命令、写代码、执行验证。这就是 Agent 和普通聊天机器人的本质区别。
我们也在持续建设端侧 AI 开发者社区。
如果你对本地 AI、Agent、端侧推理感兴趣,欢迎加入交流,一起把真正可落地的端侧 AI 生态做出来。


公司核心团队成员来自清华大学、北京大学、上海交通大学、浙江大学、密歇根大学安娜堡分校、加州大学圣地亚哥分校,以及腾讯、阿里、字节、华为、微软等顶尖高校与互联网企业。团队长期聚焦端侧模型轻量化与高效推理、端侧模型系统优化与计算加速、多端协作与端云协同推理等关键方向,持续推进系统性的技术攻关与工程实践,在相关领域形成了扎实的技术积累与较强的行业影响力。近年来,团队先后主持多项国家自然科学基金重点项目、专项重点项目、优秀青年科学基金项目及国家重点研发计划课题等国家级科研任务,并与华为、荣耀、蚂蚁、字节跳动等头部企业建立了紧密的学术与技术合作关系。
Website: https://omnimind.com.cn
Github: https://github.com/omnimind-ai
Email: info@omnimind.com.cn
预览时标签不可点